What is TREC RAG?
Our white paper will be released soon!
The (TREC) Retrieval-Augmented Generation Track is intended to foster innovation and research within the field of retrieval-augmented generation systems. This area of research focuses on combining retrieval methods - techniques for finding relevant information within large corpora with Large Language Models (LLMs) to enhance the ability of systems to produce relevant, accurate, updated and contextually appropriate content.
2024 Tasks Overview
We are conducting three tasks in TREC 2024 RAG track. These tasks are as follows:
-
(R) Retrieval Task : The “R” track requires participants to rank and retrieve the topmost relevant segments from the MS MARCO Segment v2.1 collection for the provided set of input topics, i.e., queries.
-
(AG) Augmented Generation Task : The “AG” track requires participants to generate RAG answers with attributions for supporting segments from the MS MARCO Segment v2.1 collection. Participants would need to use the top-k relevant segments provided by our baseline retrieval system.
-
(RAG) Retrieval-Augmented Task : The “RAG” track requires participants to generate RAG answers with attributions for supporting segments from the MS MARCO Segment v2.1 collection. Participants are free to choose their own retrieval system and chunking technique. We only require the participants to map their chunk to MS MARCO Segment v2.1 for reprodubicility and ease of evaluation.
Proposed Evaluation Methodology - Version 0.1
The proposed evaluation methodology for the TREC 2024 RAG track is as follows:


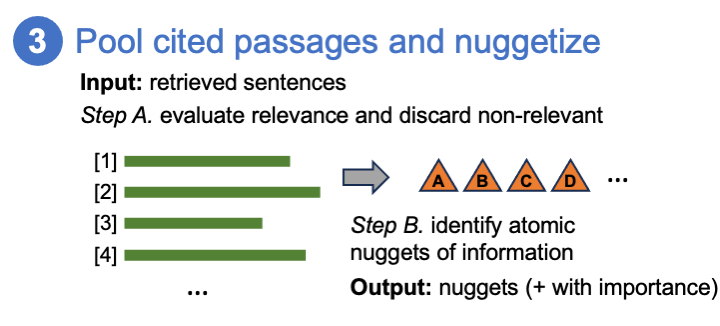
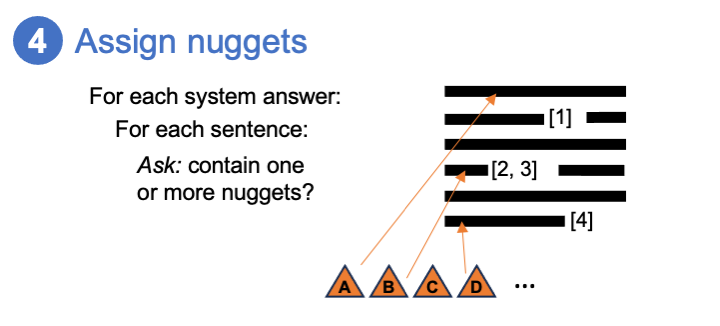

Timeline
Development Topics and baselines released: Week 1, June 2024
Final Topics released: August 4th, 2024
Submission deadline: August 11th, 2024
Results and judgments (whatever form it takes) returned to participants: October 2024
TREC 2024 Conference: November 2024
Organizers of TREC 2024 RAG Track
- Ronak Pradeep, University of Waterloo
- Nandan Thakur, University of Waterloo
- Jimmy Lin, University of Waterloo
- Nick Craswell, Microsoft