TREC 2024 RAG Evaluation Overview
Version 1.0. Last Updated: July 25, 2024
An Overview of the TREC 2024 RAG Evaluation Procedure
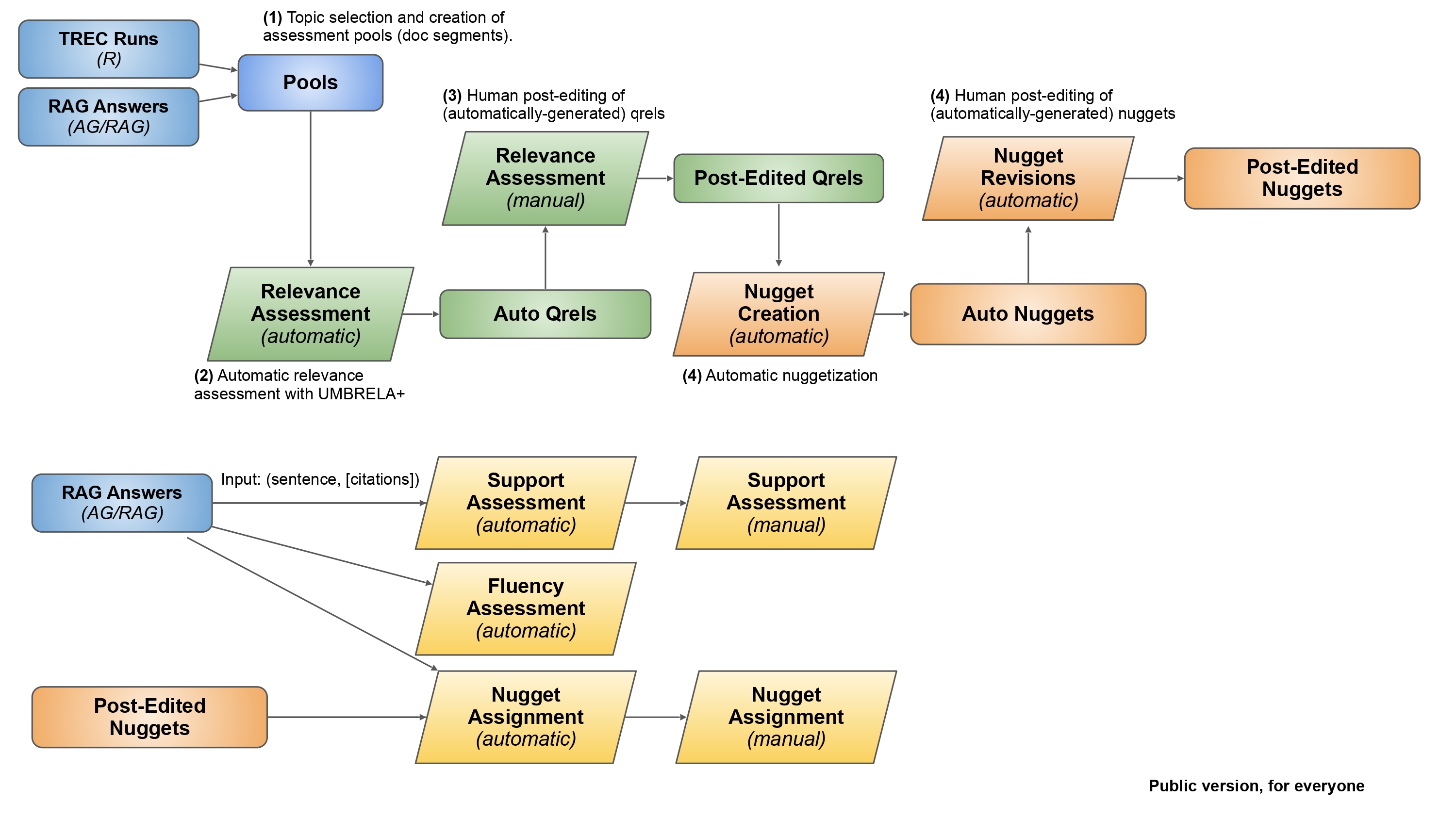
This year at the TREC 2024 Retrieval-Augmented Generation (RAG) Track, we plan to follow the evaluation pipeline in Figure 1. The top half of the workflow focuses on constructing “ground truth” information nuggets, whereas the bottom half focuses on evaluating systems’ answers based on the information nuggets. Below is an overview of each step of the pipeline:
Stage 1: Relevance Assessment
Topic Selection and Creation: The process begins with collecting responses from participants submitted to the Retrieval (R) and the Augmented-Generation (AG/RAG) tracks. The segments (or document chunks) and RAG answers provided by all the participants will be used for creating the pools for assessment, based on submission priority and availability of assessors.
Relevance Assessment (Automatic): The next step involves assessing the relevance of the pooled segments concerning the input topic (query). As the first step, we utilize various relevance estimators based on UMBRELA [1] and beyond to assess the relevance scores of each topic-segment pair. We construct the “Auto Qrels” after completing our automatic relevance assessment.
Relevance Assessment (Manual): After the automatic scoring, an additional manual assessment using human annotators is performed to refine the assigned relevance scores. We construct the “Post-Edited Qrels” which will be used for the Retrieval (R) task evaluation.
[1] Upadhyay et al. “UMBRELA: UMbrela is the (Open-Source Reproduction of the) Bing RELevance Assessor.” https://arxiv.org/abs/2406.06519.
Stage 2: Nugget Curation
Nugget Creation (Automatic): Using the relevant pooled segments for each input topic, an automatic nugget creation (or nuggetization) process leveraging LLMs to generate multiple few-word to sentence-long nuggets containing factual information relevant to the input topic. The “Auto Nuggets” list is constructed for every topic selected. These nuggets will be grounded in the corpus and span all crucial facts that an RAG answer should cover. These “Auto Nuggets” also include a binary score of vitality (‘okay’ or ‘vital’).
Nuggets Revisions (Manual): The “Auto Nuggets” list is provided to the annotators for further refinement. The annotator will cover each nugget in the list and determine its relevance to the input topic. The annotators can delete, edit, or even add new human-generated nuggets to the nugget list. After the revision round, we construct a “Post-Edited Nuggets” list which will be used for nugget-based evaluation of the AG/RAG tracks.
Stage 3: Support, Fluency & Nugget Assessment
RAG/AG Answers: After successfully generating the information nuggets and lists of relevant documents, we evaluate each participant’s RAG/AG answers using three independent evaluation metrics: (i) Support, (ii) Fluency, and (iii) Nugget assignment. Each RAG answer is broken into sentences with each sentence containing citations to retrieved segments.
Support Assessment (Automatic): The support assessment evaluates every sentence mentioned in the answer. Every sentence is first evaluated automatically using an LLM for providing any specific information requiring a citation, or if the sentence is a generic sentence requiring no citation. Next, for sentences containing citations, each sentence is evaluated for how well it is supported by its associated cited segments. We categorize support on a scale of 0-2: no, partial, or full support.
Support Assessment (Manual): The support assessment identical to the automatic stage is evaluated using a human assessor. Every sentence is judged using a human annotator to check whether the sentence requires a citation or not. Further, for sentences requiring citation, we ask each annotator to judge whether each sentence present within the RAG answer contributes no, partial, or full support for its associated cited segments.
Fluency Assessment (Automatic): The fluency assessment evaluates whether each RAG answer is fluent and cohesive. We automatically compute fluency by using the input topic and the complete RAG answer, where the LLM will score fluency.
Nugget Assessment (Automatic): The automatic nugget assessment evaluates the complete RAG response and checks for how many nuggets from the list are present within the answer. Note that we use an LLM for evaluation, not heuristic metrics like BLEU which compute the word overlap. The automatic nugget assessment computes an assignment score akin to that described in support assessment, where the nugget is either not supported by the answer, partially supported, or fully supported.
Nugget Assessment (Manual): The manual nugget assessment is a process identical to the automatic nugget assessment. We ask the assessor to manually assess how well each nugget in the Post-Edited Nuggets list is covered within the RAG answer.
Stage X: And everything else under the sun
While the above stages will likely be what we are constrained to with NIST assessors in the loop, we would like to also evaluate other aspects of RAG answers. This could be hallucination rates, contradictions across answer sentences, pairwise evaluation, etc. Anything else you’d like to see? Reach out!